

Split it. Map it. Send it. Count it!
When I think of MapReduce, I picture an army of robots shuffling numbers.
September 16, 2019
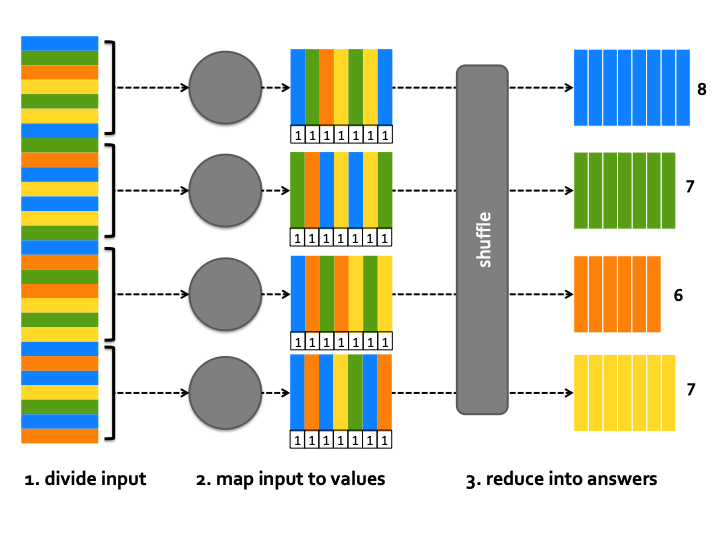
MapReduce has the best name: a MapReduce framework maps items to values and reduces the (item, value) pairs into answers. The trick is there’s many Mappers operating at the same time on their own slice of data. From now on, we’ll refer to Mapper pairs as (key, value) pairs per usual.
MapReduce and distributed file systems go together like peanut butter and jelly. Because the Mappers perform independent calculations, their data products can be stored on separate machines in a distributed system.
MapReduce comes from Google, but other technologies such as Spark and Hadoop use a MapReduce framework too. Google has since developed other technologies that replaced MapReduce however it is still used in batch processing and there’s plenty of value in learning MapReduce’s simple approach to parallelism at scale.
Our application has five steps: Split, Stem, Map, Send, and Reduce. Splitter, Stemmer, Mapper and Sender communicate using pipes. Sender connects to Reducer using TCP/IP. A bash script ties it all together and is the key to quickly and easily attaining parallel processing on a large scale. We’ll go over all the steps, but most of the magic happens in the Reducer (where we collate results from disparate Mappers) and the bash driver. GitHub project.
Split it.
If we’re going to run multiple Mappers at the same time, we need to divide up the data - we don’t want the Mappers to do duplicate work! There’s a lot of approaches that will work, but a simple one is to simply divide the input file into fourths: one for each Mapper.
You can run a MapReduce application with as many parallel processing chains as you like. We picked four.
Dividing up the file happens in the Splitter. The Splitter requires three command line arguments: input filename, number of lines in the file, and a number 1-4 specifying which processing chain we’re starting. Because it is written in java, our command line looks like this: java -classpath bin/ Splitter $filename $num_lines $i. After the Splitter calculates the range of line numbers, it prints those lines on stdout.
Wait - I thought we’re using pipes to communicate between processes?!?! We are - Unix pipes!
Stemmer is up next. It reads strings from stdin, cleans them, and prints the result on stdout. Why clean the data? Because we’re counting unique words. Consider the sentences “Programming is great fun. Everyone should try it and see how much fun programming can be.” The word “programming” appears both capitalized and lowercase; “fun” appears with and without trailing punctuation. We probably don’t care how many times stop words such as “is”, “it”, & “and” appear.
If you consider proper nouns, especially ones that aren’t always proper such as “apple” the fruit and “Apple” the company, cleaning text can get more complicated. We’re keeping it simple for now.
After Stemmer converts text to lowercase it then removes stop words and punctuation including new lines. It too prints the result on stdout.
Relevant Files
- Splitter.java
- Stemmer.java
Map it.
Next up is the Mapper; just like Stemmer, it receives input on stdin. Mapper’s task is to convert input into (key, value) pairs. Because our application is counting words, the key is a word and the value is the current count. Each item is a single word so its count is always 1.
If our application was counting daily sales for each store by ID, our (key, value) pairs would be (store ID, daily sales).
Mappers can also perform filtering. For example, we might only be interested in words beginning with “s” or how many times I can mention “data” in a single post. Mapper finishes by printing $word,1 on stdout (separated by spaces).
Relevant Files
- Mapper.java
Send it.
Sender is quite simple. Given an IP address and port number, it connects to the Reducer. It receives Mapper key,value pairs on stdin and passes them on to Reducer without making any modifications.
To keep testing easy, Sender and Reducer are independent processes on the same local machine. By changing the IP address (and perhaps adding an ssh key) we can easily make this work across multiple machines.
Relevant Files
- Sender.java
Reduce it.
There’s only one instance of the Reducer yet four processing chains feed it information. In addition to handling each input source in a new thread, the Reducer must protect its intermediate results. If shared data structures aren’t protected, threads can step on each other, cause race conditions, and report wrong answers.
The Reducer stores all intermediate results in a hash map with the word as a key and a list of numbers as the value. To avoid a race condition without blocking, we synchronize the threads and protect the hashmap with a lock.
import java.util.ArrayList;
import java.util.HashMap;
public class Reducer{
//hash table storing words and list of counts
private static HashMap<String, ArrayList<Integer>> wordTable;
//use a lock for the table
private final static Object wordLock = new Object();
...
public boolean update(String key, int val) {
//update word table with the key and value
synchronized(wordLock){
if(wordTable.containsKey(key)) {
//key exists; update entry
wordTable.get(key).add(val);
}
else {
//key doesn't exist yet; add new entry
ArrayList<Integer> tmpList = new ArrayList<Integer>();
tmpList.add(val);
wordTable.put(key, tmpList);
}
}
return true;
}
}
All threads share one lock with minimal scope and no dependencies in order to prevent deadlock. Threads only need to acquire a lock when they are modifying the hash map, wordTable.
Another fun aspect of Reducer is the barrier. How does Reducer know when it has received all expected input and it is time to add up the results? It utilizes a cyclic barrier. Barriers force a wait until the specified number of threads have finished executing. Then, an AggregatorThread takes over. It adds up the number of occurrences for each word and prints the result.
import java.util.concurrent.CyclicBarrier;
public class Reducer{
private static CyclicBarrier cyclicBarrier;
//constructor
public Reducer(){
wordTable = new HashMap<String, ArrayList<Integer>>();
cyclicBarrier = new CyclicBarrier(4,new AggregatorThread());
}
//REDUCER HANDLER
private static class ReducerHandler extends Thread implements Runnable{
public void run() {//read the input
...
//This is where the work is done by the ReducerHandler,
//takes the input line and parses it
handleMessage(inputLine);
cyclicBarrier.await();
}
} // end of ReducerHandler class
//Runs 'Tally Results' when the cyclic barrier is completed
class AggregatorThread implements Runnable{
public void tallyResults() {
for(String key: wordTable.keySet()){
// get list of numbers for key
ArrayList<Integer> counts = wordTable.get(key);
int total = addAll(counts);
System.out.println(key + " " + String.valueOf(total));
}
}
private int addAll(ArrayList<Integer> counts) {
int sum = 0;
for(int val: counts) {
sum += val;
}
return sum;
}
@Override
public void run() {
tallyResults();
}
} // end of AggregatorThread class
}
Relevant Files
- Reducer.java
Drive it!
We tested our MapReduce application along component boundaries (e.g. Splitter, Stemmer, etc) but the real fun is running all components end-to-end.
Running and testing the MapReduce application is straight-forward when using the bash script driver.sh. The driver script starts the Reducer, then calls the Splitter-Stemmer-Mapper-Sender chain four times. All Reducer output is redirected to a text file named reduce_results.txt in the current working directory. Reducer output location can easily be changed by updating driver.sh.
Here’s an example test scenario to demonstrate the MapReduce application. All steps assume you’re running from the MapReduce directory with script, and bin directories present.
$ pwd
/Users/kkunapuli/projects/MapReduce
$ ls
bin script src
Make a test file
Using vim, we have a test file (lines.txt) that repeats “Here is a test line of text. Writing text is fun.” 400 times. It will test both stop word removal and accurate counting of words. Because “is”, “a”, and “of” are all stop words, we expect the final result to be 400 counts each of “here”, “test”, “line”, “writing”, and “fun”. The word “text” appears twice; it should have a count of 800. Our test case will also exercise capitalization and punctuation removal.
$ cat lines.txt | head -5
Here is a test line of text. Writing text is fun.
Here is a test line of text. Writing text is fun.
Here is a test line of text. Writing text is fun.
Here is a test line of text. Writing text is fun.
Here is a test line of text. Writing text is fun.
$ cat lines.txt | wc -l
400
A couple reasons why I like vim:
- it’s available on even the most lightweight systems
- sometimes I just want to quickly edit a file without waiting for a text editor to start
- once you learn the commands, vim is incredibly powerful
Run MapReduce application
Run the entire MapReduce application with a single terminal command: script/driver.sh $test_file $port
Use whatever (free) port number you like - we just need to make sure Sender and Reducer use the same one. Here, $test_file is the lines.txt that we just created.
I also added a Unix time command to demonstrate that our application is indeed using four threads of execution.
$ time script/driver.sh lines.txt 778
real 0m0.519s
user 0m2.050s
sys 0m0.787s
As we can see from the time output, our application took 519 ms of “wall clock time” to execute. More interesting is that it spent 2050 ms CPU time executing. That’s approximately 4 times longer than our wall clock estimate! This is exactly what we would expect when starting four different (but equally loaded) processes to execute in parallel. Our application did indeed use four parallel processes to count the number of unique word occurrences in lines.txt.
Inspect results
All reducer output is directed to reduce_results.txt. It should contain a list of unique words in the input text file along with a count. In this case, we expect six unique words. All words except “text” will have a count of 400. Because it appears twice in our test line, “text” will have a count of 800.
$ cat reduce_results.txt
text 800
test 400
here 400
line 400
writing 400
fun 400
As you can see from the terminal output, “is”, “a”, and “of” were removed as stop words. The “.” was removed from text and it was matched correctly to the other instance of text in the second sentence. All remaining words were sent to the Mapper and Reducer and aggregated correctly. If we made a concurrency or synchronization error, there would probably be repeated words with differing counts or incorrect counts.
Why aren’t the words ordered? Because we use a hashmap to store unique words and their current count. We achieve O(1) lookup but sacrifice any kind of ordering. Even if we listed words in the order they were received in the Reducer, we wouldn’t be guaranteed the same order as the original file without introducing a significant amount of overhead.
Driver script anatomy
It’s great that our script properly executed a MapReduce application, but let’s get into the details of how everything is executed.
It’s straight-forward to call a Java program from the terminal. All you need to know is the location of the compiled class file, the name of the class, and any required command line arguments.
In this case, because we’re running from the MapReduce parent directory, class path is simply bin/. The class names for each process are simple: Splitter, Stemmer, Mapper, Sender, and Reducer. Splitter and Sender require command line arguments and they’re added to the end of the command, e.g. $filename in $cmdSplit.
#assume system is being run from project directory
cpath="bin/"
cmdSplit="java -classpath $cpath Splitter $filename $num_lines"
cmdStem="java -classpath $cpath Stemmer"
cmdMap="java -classpath $cpath Mapper"
cmdSend="java -classpath $cpath Sender $redHost $redPort"
cmdReduce="java -classpath $cpath Reducer"
Using $cmdReduce from above, start the Reducer. Add > $output_file after the command to store output in a file so we can inspect it later. This will redirect everything from Reducer stdout to $output_file. In this case, we’re using reduce_results.txt as our output file.
We also want to put the Reducer in the background using “&”. Otherwise our script will be stuck waiting for the Reducer to finish - which can’t happen without the Split | Stem | Map | Send chain.
# start reducer
($cmdReduce > reduce_results.txt) &
Just like we did for the Reducer, we want to put the MapReduce processing chain in the background and save the process ID (pid). We’re going to kick off four processing chains to run at the same time and we want to wait for all to finish at the end.
Waiting for all pids to finish is a poor man’s bash barrier.
#keep array of pids
pid_arr=(0 0 0 0)
#start all processes in background
for i in 1 2 3 4; do
#make the command for splitter i
fullCmdSplit="$cmdSplit $i"
#start all processes
($fullCmdSplit | $cmdStem | $cmdMap | $cmdSend) &
pid=$!
#store pid
idx=`echo "$i - 1" | bc -l`
pid_arr[$idx]=$pid
done
#wait on all pids
for p in "${pid_arr[@]}"; do
wait $p
done
If we run the Splitter, Stemmer, or Mapper on its own we’ll see its output in the terminal because it’s written to stdout. Stemmer, Mapper, and Sender read from stdin allowing us to test them as standalone processes. First direct a string to their stdin then examine the terminal output. For example, I can test the Stemmer with echo and a pipe:
$ echo "World is greeted." | $cmdStem
world greeted
Echo prints our string “World is greeted.” to stdout, but redirects it to Stemmer stdin instead of displaying it in the terminal. We see Stemmer’s stdout in the terminal and are happy to note punctuation and the stop word “is” has been removed.
It’s important that our processes read from stdin and write to stdout because it allows us to connect them with unix pipes instead of TCP/IP communication! Unix pipes are a lot simpler to use, and it makes our code easier to test. It also makes it easier to change the code for a different MapReduce application. We could even insert a C or Python script in the processing chain if we wanted!
A unix pipe simply directs stdout from the first process to stdin of the second process. It’s used all the time to chain together unix commands. In fact, we’ve used it many times already: to get a line count of our input file (cat $filename | wc -l), and print only the first five lines of our test file (cat lines.txt | head -5).
So far we’ve only talked about chaining together two processes but Unix doesn’t limit us. We can chain together multiple processes. In fact, that’s exactly what we’ve done in the driver script: Splitter output is sent to Stemmer’s stdin, Stemmer’s stdout is sent to Mapper’s stdin, and Mapper’s stdout is redirected to Sender’s stdin. Sender connects with Reducer through traditional TCP/IP communication.
We want to save and store the pid of the processing chain using $!. We use a command line calculator, bc -l, to do a little math and subtract one from “quarter” to get the array index. We also could have made our array with five elements and skipped index 0.
And that’s all there is to it! Next, we’ll see how easy it is to switch out Mapper to solve a different problem.
Relevant Files
- script/driver.sh